Below is another complete example showing how sassy functions interact with tidyverse to create a survival analysis. This is the most complicated example in the documentation.
Program
There are several interesting aspects to this report. The first is that the reporter package gives you the freedom to perform any analysis you want. Any statistics that R can produce may be added to a reporter report. You just need to get them into a data frame or plot, and the reporter package will render the analysis as desired.
Second, observe the ability to append both tabular and plot content onto the same report. This appending ability was designed into the reporter package from the beginning, and gives you the flexibility you need to document your entire analysis.
Finally, notice that the table on page one is a complex table, that
is actually composed of two tables stacked on top of one another. The
first table tbl1 contains the column headers and some PSGA
counts. The second table tbl2 is marked as
headerless and contains the Kaplan-Meier analysis. The two
tables are lined up so they appear as one table. This technique of
stacking one table on top of another allows you to create very complex
tables in a straight-forward manner.
library(tidyverse)
library(sassy)
library(broom)
library(survival)
library(survminer)
options("logr.autolog" = TRUE,
"logr.notes" = FALSE)
# Get temp location for log and report output
tmp <- tempdir()
# Open Log
lf <- log_open(file.path(tmp, "example7.log"))
# Load and Filter Data --------------------------------------------------
sep("Load and Filter Data")
# Get path to sample data
pkg <- system.file("extdata", package = "sassy")
# Get adam data
libname(adam, pkg, "sas7bdat")
# Filter data
adsl <- adam$adsl |>
select(USUBJID, SEX, AGEGR1, AGE, ARM) |>
filter(ARM != "SCREEN FAILURE") |> put()
adpsga <- adam$adpsga |>
filter(PARAMCD =="PSGA" & TRTA != "" & !is.na(AVISITN)) |>
select(USUBJID, TRTA, AVISIT, AVISITN, AVAL, CRIT1FL) |> put()
# Get population counts
arm_pop <- adsl |> count(ARM) |> deframe() |> put()
# Prepare Data ------------------------------------------------------------
sep("Prepare data for analysis")
put("Determine minimum visit at which success was achieved")
adpsga_minvsuccess <-
adpsga |>
filter(CRIT1FL == 'Y') |>
group_by(USUBJID) |>
summarize(minvisit = min(AVISITN))
put("Get subjects which did not achieve success")
adpsga_nosuccess <-
anti_join(adpsga, adpsga_minvsuccess, by = ('USUBJID')) |>
group_by(USUBJID) |>
summarize(maxvisit = max(AVISITN))
put("Combine subjects cured with subjects not cured")
adslpsga_final <-
inner_join(adsl, adpsga, by = c('USUBJID')) |>
left_join(adpsga_minvsuccess, by = c('USUBJID')) |>
left_join(adpsga_nosuccess, by = c('USUBJID')) |>
filter((AVISITN == minvisit & !is.na(minvisit)) |
(AVISITN == maxvisit & !is.na(maxvisit))) |>
mutate(cured = case_when(CRIT1FL == "Y" ~ TRUE,
TRUE ~ as.logical(FALSE))) |>
select(-minvisit, -maxvisit)
# Counts ---------------------------------------------------------------
sep("Perform Counts and Statistical Tests")
put("Count patients with PSGA <= 1")
success_counts <- adslpsga_final |>
filter(cured == TRUE) |>
count(TRTA) |>
pivot_wider(names_from = TRTA,
values_from = n) |>
transmute(block = "counts",
label = "Number of patients with PSGA <= 1",
"ARM A" = as.character(`ARM A`),
"ARM B" = as.character(`ARM B`),
"ARM C" = as.character(`ARM C`),
"ARM D" = as.character(`ARM D`)) |>
put()
put("Count patients with PSGA > 1")
failed_counts <- adslpsga_final |>
filter(cured == FALSE) |>
count(TRTA) |>
pivot_wider(names_from = TRTA,
values_from = n) |>
transmute(block = "counts",
label = "Number of Censored Subjects (PSGA > 1)",
"ARM A" = as.character(`ARM A`),
"ARM B" = as.character(`ARM B`),
"ARM C" = as.character(`ARM C`),
"ARM D" = as.character(`ARM D`)) |>
put()
count_block <- bind_rows(success_counts, failed_counts)
# Kaplan-Meier estimates ----------------------------------------------------
sep("Perform Kaplan-Meier Tests")
put("Create survival vector")
surv_vct <- Surv(time = adslpsga_final$AVISITN, event = adslpsga_final$cured) |>
put()
put("Fit model on survival vector")
stats_survfit_trta <- survival::survfit(surv_vct ~ TRTA, data = adslpsga_final, ) |>
put()
put("Get model quantiles")
stats_survfit_quantiles <- quantile(stats_survfit_trta)
put("Get lower confidence intervals")
ci_lower <-
as.data.frame(stats_survfit_quantiles$lower) |>
rownames_to_column() |>
mutate(block = "surv",
TRTA = substring(rowname,6)) |>
pivot_longer(cols = c(`25`, `50`, `75`),
names_to = "Q",
values_to = "lower") |>
put()
put("Get upper confidence intervals")
ci_upper <-
as.data.frame(stats_survfit_quantiles$upper) |>
rownames_to_column() |>
mutate(block = "surv",
TRTA = substring(rowname,6)) |>
pivot_longer(cols = c(`25`, `50`, `75`),
names_to = "Q",
values_to = "upper") |>
put()
put("Get confidence intervals")
ci <-
inner_join(ci_lower, ci_upper) |>
mutate(ci = paste0("(", ifelse(is.na(lower), "-", lower)
, ", ", ifelse(is.na(upper), "-", upper), ")")) |>
pivot_wider(id_cols = c("block", "Q"),
names_from = TRTA,
values_from = ci) |>
mutate(order=2,
label1 = case_when(Q == 25 ~ "25th percentile (weeks)",
Q == 50 ~ "Median (weeks)",
Q == 75 ~ "75th percentile (weeks)"),
label2 = "95% Confidence Interval**") |>
select(block, Q, order, label1, label2,
`ARM A`, `ARM B`, `ARM C`, `ARM D`) |>
put()
put("Get quantiles")
quants <-
as.data.frame(stats_survfit_quantiles$quantile) |>
rownames_to_column() |>
mutate(block = "surv",
TRTA = substring(rowname,6)) |>
pivot_longer(cols = c(`25`, `50`, `75`),
names_to = "Q",
values_to = "value") |>
pivot_wider(id_cols = c("block", "Q"),
names_from = TRTA,
values_from = value) |>
mutate(order=1,
label1 = case_when(Q == 25 ~ "25th percentile (weeks)",
Q == 50 ~ "Median (weeks)",
Q == 75 ~ "75th percentile (weeks)"),
label2 = "",
`ARM A` = as.character(`ARM A`),
`ARM B` = as.character(`ARM B`),
`ARM C` = as.character(`ARM C`),
`ARM D` = as.character(`ARM D`)) |>
select(block, Q, order, label1, label2,
`ARM A`, `ARM B`, `ARM C`, `ARM D`) |>
put()
put("Final arrangement")
kaplan_block <-
bind_rows(quants, ci) |>
arrange(block, Q, order) |>
transmute(block,
label1,
label2 = ifelse(label2 == "", NA, label2),
`ARM A`, `ARM B`, `ARM C`, `ARM D`) |>
put()
# Cox Proportional Hazards -----------------------------------------------
sep("Perform Cox Proportional Hazards Test")
put("Run Cox tests")
stats_surv_cph <- survival::coxph(surv_vct ~ TRTA, data = adslpsga_final) |>
put()
put("Create summary statistics on Cox results")
cph_summary <-
summary(stats_surv_cph) |>
put()
put("Extract coefficients")
cph_coef <-
as.data.frame(cph_summary$coefficients) |>
rownames_to_column() |>
mutate(block = "surv",
TRTA = substring(rowname,5)) |>
put()
put("Extract confidence intervals")
cph_ci <-
cph_summary$conf.int |>
as.data.frame(cph_summary$conf) |>
rownames_to_column() |>
put()
put("Create cox statistics block")
cox_block <-
bind_cols(cph_coef, cph_ci) |>
rename(hazard = `exp(coef)...3`, pval = `Pr(>|z|)`,
lower = `lower .95`, upper = `upper .95`) |>
select(TRTA, hazard, pval, lower, upper) |>
mutate(block = "cox",
ci = paste0("(", ifelse(is.na(lower), "-", sprintf("%.2f", lower))
, ", ", ifelse(is.na(upper), "-", sprintf("%.2f", upper)), ")"),
hazard = sprintf("%.2f", hazard),
pval = sprintf("%.3f", pval)) |>
pivot_longer(cols = c("hazard", "pval", "ci"),
names_to = "stat",
values_to = "value") |>
pivot_wider(id_cols = c("block", "stat"),
names_from = TRTA,
values_from = value) |>
mutate(label1 = case_when(stat == "hazard"
~ "Hazard Ratio (Each Treatment Group - ARM A)***",
stat == "pval" ~ "P-value",
TRUE ~ "95% CI of Hazard Ratio"),
label2 = as.character(NA),
`ARM A` = as.character(NA)) |>
select(block, label1, label2, `ARM A`, `ARM B`, `ARM C`, `ARM D`) |>
put()
put("Combine statistics blocks")
stat_block <- bind_rows(kaplan_block, cox_block) |> put()
# Create Survival Plot -------------------------------------------------------
sep("Create survival plot")
put("Create data frame with zero values for each visit")
arms <- unique(adslpsga_final$ARM)
visits <- unique(adslpsga_final$AVISITN)
all_visits <- rep(arms, length(visits))
all_visits <- all_visits[order(all_visits)]
put("Create visit template")
df <- data.frame(ARM = all_visits,
AVISIT = paste("Week", visits),
AVISITN = visits,
cured = FALSE) |> put()
put("Calculate cummulative sum and percent")
adslpsga_plot <- adslpsga_final |>
select(ARM, AVISIT, AVISITN, cured) |>
bind_rows(df) |>
group_by(ARM, AVISIT, AVISITN) |>
summarize(sumc = sum(cured)) |>
arrange(ARM, AVISITN) |>
group_by(ARM) |>
mutate(AVISIT = ifelse(AVISIT == "Week 0", "Day 1 Baseline", AVISIT),
csumc = cumsum(sumc)) |>
distinct() |>
mutate(pct = case_when(ARM == "ARM A" ~ csumc / arm_pop["ARM A"],
ARM == "ARM B" ~ csumc / arm_pop["ARM B"],
ARM == "ARM C" ~ csumc / arm_pop["ARM C"],
ARM == "ARM D" ~ csumc / arm_pop["ARM D"])) |>
put()
# Add factor to ensure sort order is correct
adslpsga_plot$AVISIT <- factor(adslpsga_plot$AVISIT,
levels = c("Day 1 Baseline",
"Week 2",
"Week 4",
"Week 6",
"Week 8",
"Week 12",
"Week 16"))
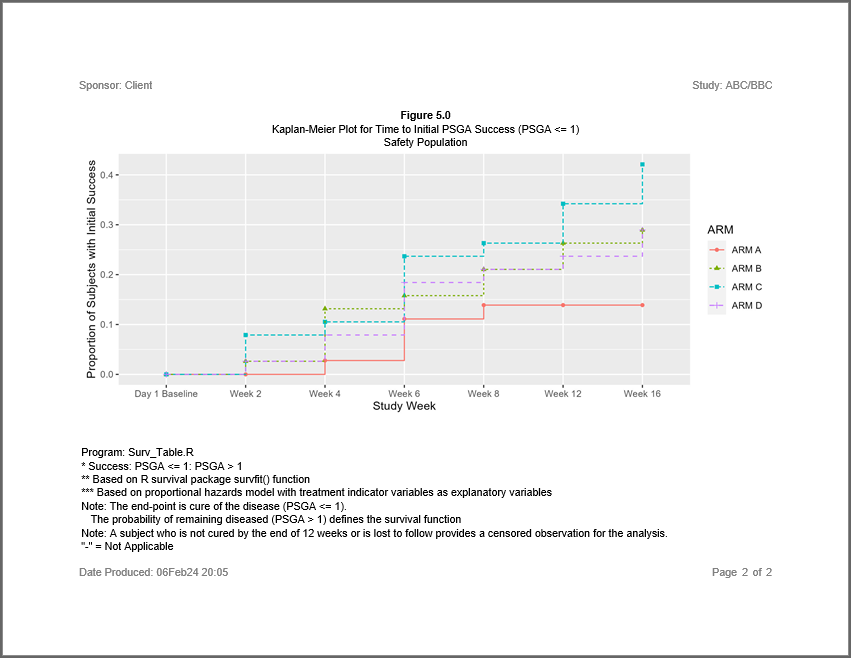
put("Generate plot")
surv_gg <- adslpsga_plot |>
ggplot(mapping = aes(y = pct, x = AVISIT , group = ARM)) +
geom_point(aes(shape = ARM, color = ARM)) +
geom_step(aes(linetype = ARM, color = ARM)) +
scale_x_discrete(name = "Study Week") +
scale_y_continuous(name = "Proportion of Subjects with Initial Success")
# Print Report ------------------------------------------------------------
sep("Create and print report")
# Create Table 1 with header
tbl1 <- create_table(count_block, width = 9) |>
column_defaults(from = `ARM A`, to = `ARM D`, align = "center", width = 1.1) |>
define(block, visible = FALSE) |>
define(label, label = "", width = 4.25) |>
define(`ARM A`, n = arm_pop["ARM A"]) |>
define(`ARM B`, n = arm_pop["ARM B"]) |>
define(`ARM C`, n = arm_pop["ARM C"]) |>
define(`ARM D`, n = arm_pop["ARM D"]) |>
titles("Table 5.0", bold = TRUE, blank_row = "above") |>
titles("Analysis of Time to Initial PSGA Success* in Weeks",
"Safety Population")
label_lookup <- c(surv = "Kaplan-Meier estimates",
cox = "Results of Proportional Hazards Regression Analysis")
# Create table 2 for statistics with stub and without header
tbl2 <- create_table(stat_block, width = 9, headerless = TRUE) |>
column_defaults(from = `ARM A`, to = `ARM D`, align = "center", width = 1.1) |>
stub(c(block, label1, label2), width = 4.25) |>
define(block, label_row = TRUE, format = label_lookup, blank_after = TRUE) |>
define(label1, indent = .25) |>
define(label2, indent = .5) |>
define(`ARM A`) |>
define(`ARM B`) |>
define(`ARM C`) |>
define(`ARM D`)
# Create plot
plt <- create_plot(surv_gg, 3.5, 9) |>
titles("Figure 5.0", bold = TRUE, blank_row = "above") |>
titles("Kaplan-Meier Plot for Time to Initial PSGA Success (PSGA <= 1)",
"Safety Population", blank_row = "none")
put("Create Report")
# Add table 1, table 2, and plot content to the same report.
# Plot will be on a separate page with it's own title.
rpt <- create_report(file.path(tmp, "output/example7.rtf"), output_type = "RTF",
font = "Arial", missing = "-") |>
set_margins(top = 1, bottom = 1) |>
page_header("Sponsor: Client", "Study: ABC/BBC") |>
add_content(tbl1, page_break = FALSE) |>
add_content(tbl2) |>
add_content(plt) |>
footnotes("Program: Surv_Table.R",
"* Success: PSGA <= 1: PSGA > 1",
"** Based on R survival package survfit() function",
paste("*** Based on proportional hazards model with treatment",
"indicator variables as explanatory variables"),
paste("Note: The end-point is cure of the disease (PSGA <= 1)."),
" The probability of remaining diseased (PSGA > 1) defines the survival function",
paste("Note: A subject who is not cured by the end of 12 weeks or is lost",
"to follow provides a censored observation for the analysis."),
"\"-\" = Not Applicable") |>
page_footer("Date Produced: " %p% fapply(Sys.time(), "%d%b%y %H:%M"),
right = "Page [pg] of [tpg]")
put("Write out the report")
res <- write_report(rpt)
# Clean Up ----------------------------------------------------------------
sep("Clean Up")
# Close log
log_close()
# View report
# file.show(res$file_path)
# View log
# file.show(lf)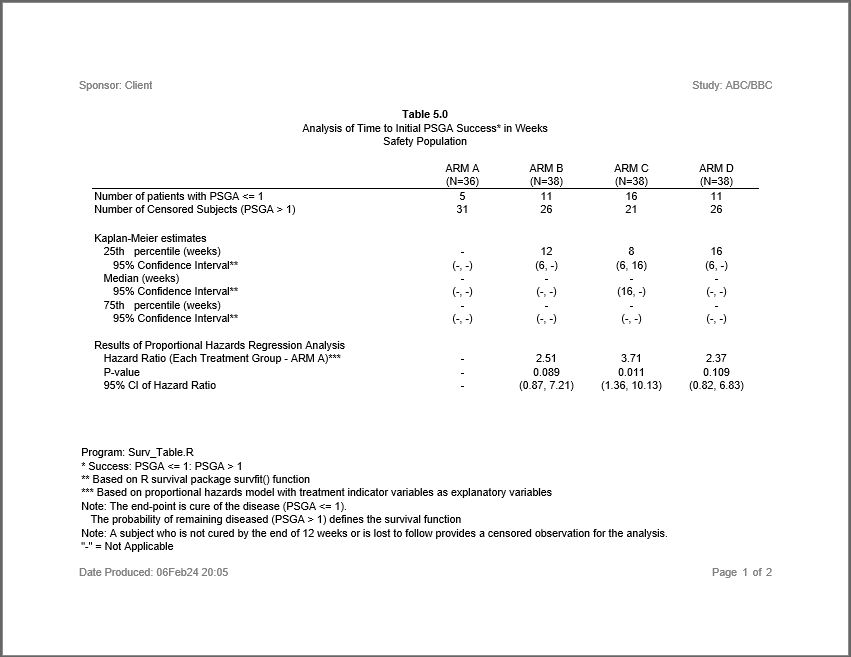
Log
The above program produces the following log:
=========================================================================
Log Path: C:/Users/dbosa/AppData/Local/Temp/RtmpgrpGQ1/log/example7.log
Program Path: C:\packages\Testing\example7.R
Working Directory: C:/packages/Testing
User Name: dbosa
R Version: 4.1.2 (2021-11-01)
Machine: SOCRATES x86-64
Operating System: Windows 10 x64 build 19041
Base Packages: stats graphics grDevices utils datasets methods base
Other Packages: tidylog_1.0.2 survminer_0.4.9 ggpubr_0.4.0 survival_3.2-13 broom_0.7.10
reporter_1.2.6 libr_1.2.1 fmtr_1.5.4 logr_1.2.7 sassy_1.0.5
forcats_0.5.1 stringr_1.4.0 dplyr_1.0.7 purrr_0.3.4 readr_2.0.2
tidyr_1.1.4 tibble_3.1.5 ggplot2_3.3.5 tidyverse_1.3.1
Log Start Time: 2021-11-21 15:30:37
=========================================================================
=========================================================================
Load and Filter Data
=========================================================================
# library 'adam': 2 items
- attributes: sas7bdat not loaded
- path: C:/Users/dbosa/Documents/R/win-library/4.1/reporter/extdata
- items:
Name Extension Rows Cols Size
1 adpsga sas7bdat 1206 42 424.8 Kb
2 adsl sas7bdat 152 56 98.7 Kb
LastModified
1 2021-10-09 13:57:48
2 2021-10-09 13:57:48
select: dropped 51 variables (STUDYID, SUBJID, SITEID, AGEU, RACE, <U+0085>)
filter: removed 2 rows (1%), 150 rows remaining
# A tibble: 150 x 5
USUBJID SEX AGEGR1 AGE ARM
<chr> <chr> <chr> <dbl> <chr>
1 ABC-01-049 M 30-39 years 39 ARM D
2 ABC-01-050 M 40-49 years 47 ARM B
3 ABC-01-051 M 30-39 years 34 ARM A
4 ABC-01-052 F 40-49 years 45 ARM C
5 ABC-01-053 F 18-29 years 26 ARM B
6 ABC-01-054 M 40-49 years 44 ARM D
7 ABC-01-055 F 40-49 years 47 ARM C
8 ABC-01-056 M 30-39 years 31 ARM A
9 ABC-01-113 M >65 years 74 ARM D
10 ABC-01-114 F >65 years 72 ARM B
# ... with 140 more rows
filter: removed 256 rows (21%), 950 rows remaining
select: dropped 36 variables (STUDYID, SUBJID, SITEID, QSSEQ, TRTP, <U+0085>)
# A tibble: 950 x 6
USUBJID TRTA AVISIT AVISITN AVAL
<chr> <chr> <chr> <dbl> <dbl>
1 ABC-01-049 ARM D Day 1 Bas~ 0 3
2 ABC-01-049 ARM D Week 2 2 2
3 ABC-01-049 ARM D Week 4 4 3
4 ABC-01-049 ARM D Week 6 6 3
5 ABC-01-049 ARM D Week 8 8 2
6 ABC-01-049 ARM D Week 8 8 2
7 ABC-01-049 ARM D Week 12 12 2
8 ABC-01-049 ARM D Week 16 16 3
9 ABC-01-050 ARM B Day 1 Bas~ 0 3
10 ABC-01-050 ARM B Week 2 2 3
# ... with 940 more rows, and 1 more
# variable: CRIT1FL <chr>
count: now 4 rows and 2 columns, ungrouped
ARM A ARM B ARM C ARM D
36 38 38 38
=========================================================================
Prepare data for analysis
=========================================================================
Determine minimum visit at which success was achieved
filter: removed 833 rows (88%), 117 rows remaining
group_by: one grouping variable (USUBJID)
summarize: now 43 rows and 2 columns, ungrouped
Get subjects which did not achieve success
anti_join: added no columns
> rows only in x 659
> rows only in y ( 0)
> matched rows (291)
> =====
> rows total 659
group_by: one grouping variable (USUBJID)
summarize: now 102 rows and 2 columns, ungrouped
Combine subjects cured with subjects not cured
inner_join: added 5 columns (TRTA, AVISIT, AVISITN, AVAL, CRIT1FL)
> rows only in x ( 5)
> rows only in y ( 0)
> matched rows 950 (includes duplicates)
> =====
> rows total 950
left_join: added one column (minvisit)
> rows only in x 659
> rows only in y ( 0)
> matched rows 291
> =====
> rows total 950
left_join: added one column (maxvisit)
> rows only in x 291
> rows only in y ( 0)
> matched rows 659
> =====
> rows total 950
filter: removed 803 rows (85%), 147 rows remaining
mutate: new variable 'cured' (logical) with 2 unique values and 0% NA
select: dropped 2 variables (minvisit, maxvisit)
=========================================================================
Perform Counts and Statistical Tests
=========================================================================
Count patients with PSGA <= 1
filter: removed 104 rows (71%), 43 rows remaining
count: now 4 rows and 2 columns, ungrouped
pivot_wider: reorganized (TRTA, n) into (ARM A, ARM B, ARM C, ARM D) [was 4x2, now 1x4]
transmute: new variable 'block' (character) with one unique value and 0% NA
new variable 'label' (character) with one unique value and 0% NA
converted 'ARM A' from integer to character (0 new NA)
converted 'ARM B' from integer to character (0 new NA)
converted 'ARM C' from integer to character (0 new NA)
converted 'ARM D' from integer to character (0 new NA)
# A tibble: 1 x 6
block label `ARM A` `ARM B` `ARM C`
<chr> <chr> <chr> <chr> <chr>
1 counts Number of ~ 5 11 16
# ... with 1 more variable: ARM D <chr>
Count patients with PSGA > 1
filter: removed 43 rows (29%), 104 rows remaining
count: now 4 rows and 2 columns, ungrouped
pivot_wider: reorganized (TRTA, n) into (ARM A, ARM B, ARM C, ARM D) [was 4x2, now 1x4]
transmute: new variable 'block' (character) with one unique value and 0% NA
new variable 'label' (character) with one unique value and 0% NA
converted 'ARM A' from integer to character (0 new NA)
converted 'ARM B' from integer to character (0 new NA)
converted 'ARM C' from integer to character (0 new NA)
converted 'ARM D' from integer to character (0 new NA)
# A tibble: 1 x 6
block label `ARM A` `ARM B` `ARM C`
<chr> <chr> <chr> <chr> <chr>
1 counts Number of ~ 31 26 21
# ... with 1 more variable: ARM D <chr>
=========================================================================
Perform Kaplan-Meier Tests
=========================================================================
Create survival vector
[1] 16+ 12+ 12+ 4 12+ 12+ 12+ 6 16+
[10] 4 16+ 16+ 16+ 16+ 16+ 2 16+ 16+
[19] 16+ 16+ 16+ 8 16 16+ 16+ 16+ 16+
[28] 16+ 16+ 16+ 16+ 16+ 16+ 2 16+ 16+
[37] 8 16+ 16+ 16+ 16+ 16+ 16+ 16+ 16+
[46] 16+ 12 16+ 16+ 16+ 12+ 4 16+ 16+
[55] 12+ 2 12 4 16+ 6 6 6 12
[64] 16+ 16+ 16 12+ 12+ 8+ 12+ 12+ 6+
[73] 12 12 16+ 16+ 0+ 6 16+ 16+ 16+
[82] 16 16+ 12+ 12+ 4 16 6 4 6
[91] 16+ 16+ 6 6+ 16+ 8 16+ 16+ 16+
[100] 16+ 16+ 16+ 6 4+ 16+ 12+ 6 16+
[109] 8 2 12+ 8 16+ 16+ 16 6 16+
[118] 12+ 2+ 16+ 4 16+ 16+ 12+ 16+ 16+
[127] 16+ 12 16 16+ 16+ 12+ 6 16+ 16+
[136] 2 4 16+ 16+ 16+ 16+ 12+ 12+ 16+
[145] 16+ 16+ 6
Fit model on survival vector
Call: survfit(formula = surv_vct ~ TRTA, data = adslpsga_final)
n events median 0.95LCL 0.95UCL
TRTA=ARM A 36 5 NA NA NA
TRTA=ARM B 37 11 NA NA NA
TRTA=ARM C 37 16 NA 16 NA
TRTA=ARM D 37 11 NA NA NA
Get model quantiles
Get lower confidence intervals
mutate: new variable 'block' (character) with one unique value and 0% NA
new variable 'TRTA' (character) with 4 unique values and 0% NA
pivot_longer: reorganized (25, 50, 75) into (Q, lower) [was 4x6, now 12x5]
# A tibble: 12 x 5
rowname block TRTA Q lower
<chr> <chr> <chr> <chr> <dbl>
1 TRTA=ARM A surv ARM A 25 NA
2 TRTA=ARM A surv ARM A 50 NA
3 TRTA=ARM A surv ARM A 75 NA
4 TRTA=ARM B surv ARM B 25 6
5 TRTA=ARM B surv ARM B 50 NA
6 TRTA=ARM B surv ARM B 75 NA
7 TRTA=ARM C surv ARM C 25 6
8 TRTA=ARM C surv ARM C 50 16
9 TRTA=ARM C surv ARM C 75 NA
10 TRTA=ARM D surv ARM D 25 6
11 TRTA=ARM D surv ARM D 50 NA
12 TRTA=ARM D surv ARM D 75 NA
Get upper confidence intervals
mutate: new variable 'block' (character) with one unique value and 0% NA
new variable 'TRTA' (character) with 4 unique values and 0% NA
pivot_longer: reorganized (25, 50, 75) into (Q, upper) [was 4x6, now 12x5]
# A tibble: 12 x 5
rowname block TRTA Q upper
<chr> <chr> <chr> <chr> <dbl>
1 TRTA=ARM A surv ARM A 25 NA
2 TRTA=ARM A surv ARM A 50 NA
3 TRTA=ARM A surv ARM A 75 NA
4 TRTA=ARM B surv ARM B 25 NA
5 TRTA=ARM B surv ARM B 50 NA
6 TRTA=ARM B surv ARM B 75 NA
7 TRTA=ARM C surv ARM C 25 16
8 TRTA=ARM C surv ARM C 50 NA
9 TRTA=ARM C surv ARM C 75 NA
10 TRTA=ARM D surv ARM D 25 NA
11 TRTA=ARM D surv ARM D 50 NA
12 TRTA=ARM D surv ARM D 75 NA
Get confidence intervals
inner_join: added one column (upper)
> rows only in x ( 0)
> rows only in y ( 0)
> matched rows 12
> ====
> rows total 12
mutate: new variable 'ci' (character) with 4 unique values and 0% NA
pivot_wider: reorganized (rowname, TRTA, lower, upper, ci) into (ARM A, ARM B, ARM C, ARM D) [was 12x7, now 3x6]
mutate: new variable 'order' (double) with one unique value and 0% NA
new variable 'label1' (character) with 3 unique values and 0% NA
new variable 'label2' (character) with one unique value and 0% NA
select: columns reordered (block, Q, order, label1, label2, <U+0085>)
# A tibble: 3 x 9
block Q order label1 label2 `ARM A`
<chr> <chr> <dbl> <chr> <chr> <chr>
1 surv 25 2 25th p~ 95% Co~ (-, -)
2 surv 50 2 Median ~ 95% Co~ (-, -)
3 surv 75 2 75th p~ 95% Co~ (-, -)
# ... with 3 more variables: ARM B <chr>,
# ARM C <chr>, ARM D <chr>
Get quantiles
mutate: new variable 'block' (character) with one unique value and 0% NA
new variable 'TRTA' (character) with 4 unique values and 0% NA
pivot_longer: reorganized (25, 50, 75) into (Q, value) [was 4x6, now 12x5]
pivot_wider: reorganized (rowname, TRTA, value) into (ARM A, ARM B, ARM C, ARM D) [was 12x5, now 3x6]
mutate: converted 'ARM A' from double to character (0 new NA)
converted 'ARM B' from double to character (0 new NA)
converted 'ARM C' from double to character (0 new NA)
converted 'ARM D' from double to character (0 new NA)
new variable 'order' (double) with one unique value and 0% NA
new variable 'label1' (character) with 3 unique values and 0% NA
new variable 'label2' (character) with one unique value and 0% NA
select: columns reordered (block, Q, order, label1, label2, <U+0085>)
# A tibble: 3 x 9
block Q order label1 label2 `ARM A`
<chr> <chr> <dbl> <chr> <chr> <chr>
1 surv 25 1 25th pe~ "" <NA>
2 surv 50 1 Median (~ "" <NA>
3 surv 75 1 75th pe~ "" <NA>
# ... with 3 more variables: ARM B <chr>,
# ARM C <chr>, ARM D <chr>
Final arrangement
transmute: dropped 2 variables (Q, order)
changed 3 values (50%) of 'label2' (3 new NA)
# A tibble: 6 x 7
block label1 label2 `ARM A` `ARM B`
<chr> <chr> <chr> <chr> <chr>
1 surv 25th per~ <NA> <NA> 12
2 surv 25th per~ 95% Conf~ (-, -) (6, -)
3 surv Median (w~ <NA> <NA> <NA>
4 surv Median (w~ 95% Conf~ (-, -) (-, -)
5 surv 75th per~ <NA> <NA> <NA>
6 surv 75th per~ 95% Conf~ (-, -) (-, -)
# ... with 2 more variables: ARM C <chr>,
# ARM D <chr>
=========================================================================
Perform Cox Proportional Hazards Test
=========================================================================
Run Cox tests
Call:
survival::coxph(formula = surv_vct ~ TRTA, data = adslpsga_final)
coef exp(coef) se(coef) z
TRTAARM B 0.9185 2.5055 0.5395 1.703
TRTAARM C 1.3111 3.7102 0.5127 2.557
TRTAARM D 0.8648 2.3744 0.5394 1.603
p
TRTAARM B 0.0886
TRTAARM C 0.0105
TRTAARM D 0.1089
Likelihood ratio test=7.87 on 3 df, p=0.04877
n= 147, number of events= 43
Create summary statistics on Cox results
Call:
survival::coxph(formula = surv_vct ~ TRTA, data = adslpsga_final)
n= 147, number of events= 43
coef exp(coef) se(coef) z
TRTAARM B 0.9185 2.5055 0.5395 1.703
TRTAARM C 1.3111 3.7102 0.5127 2.557
TRTAARM D 0.8648 2.3744 0.5394 1.603
Pr(>|z|)
TRTAARM B 0.0886 .
TRTAARM C 0.0105 *
TRTAARM D 0.1089
---
Signif. codes: 0 <U+0091>***<U+0092> 0.001 <U+0091>**<U+0092> 0.01 <U+0091>*<U+0092> 0.05 <U+0091>.<U+0092>
0.1 <U+0091> <U+0092> 1
exp(coef) exp(-coef) lower .95
TRTAARM B 2.505 0.3991 0.8704
TRTAARM C 3.710 0.2695 1.3584
TRTAARM D 2.374 0.4212 0.8249
upper .95
TRTAARM B 7.212
TRTAARM C 10.134
TRTAARM D 6.834
Concordance= 0.61 (se = 0.042 )
Likelihood ratio test= 7.87 on 3 df, p=0.05
Wald test = 6.68 on 3 df, p=0.08
Score (logrank) test = 7.32 on 3 df, p=0.06
Extract coefficients
mutate: new variable 'block' (character) with one unique value and 0% NA
new variable 'TRTA' (character) with 3 unique values and 0% NA
rowname coef exp(coef) se(coef)
1 TRTAARM B 0.9184774 2.505473 0.5394543
2 TRTAARM C 1.3110748 3.710159 0.5126631
3 TRTAARM D 0.8647564 2.374428 0.5394037
z Pr(>|z|) block TRTA
1 1.702605 0.08864206 surv ARM B
2 2.557381 0.01054637 surv ARM C
3 1.603171 0.10889687 surv ARM D
Extract confidence intervals
rowname exp(coef) exp(-coef) lower .95
1 1 2.505473 0.3991263 0.8703729
2 2 3.710159 0.2695302 1.3583539
3 3 2.374428 0.4211541 0.8249311
upper .95
1 7.212304
2 10.133796
3 6.834396
Create cox statistics block
rename: renamed 4 variables (hazard, pval, lower, upper)
select: dropped 8 variables (rowname...1, coef, se(coef), z, block, <U+0085>)
mutate: converted 'hazard' from double to character (0 new NA)
converted 'pval' from double to character (0 new NA)
new variable 'block' (character) with one unique value and 0% NA
new variable 'ci' (character) with 3 unique values and 0% NA
pivot_longer: reorganized (hazard, pval, ci) into (stat, value) [was 3x7, now 9x6]
pivot_wider: reorganized (TRTA, lower, upper, value) into (ARM B, ARM C, ARM D) [was 9x6, now 3x5]
mutate: new variable 'label1' (character) with 3 unique values and 0% NA
new variable 'label2' (character) with one unique value and 100% NA
new variable 'ARM A' (character) with one unique value and 100% NA
select: dropped one variable (stat)
# A tibble: 3 x 7
block label1 label2 `ARM A` `ARM B`
<chr> <chr> <chr> <chr> <chr>
1 cox Hazard Ratio~ <NA> <NA> 2.51
2 cox P-value <NA> <NA> 0.089
3 cox 95% CI of Ha~ <NA> <NA> (0.87,~
# ... with 2 more variables: ARM C <chr>,
# ARM D <chr>
Combine statistics blocks
# A tibble: 9 x 7
block label1 label2 `ARM A` `ARM B`
<chr> <chr> <chr> <chr> <chr>
1 surv 25th perc~ <NA> <NA> 12
2 surv 25th perc~ 95% Con~ (-, -) (6, -)
3 surv Median (we~ <NA> <NA> <NA>
4 surv Median (we~ 95% Con~ (-, -) (-, -)
5 surv 75th perc~ <NA> <NA> <NA>
6 surv 75th perc~ 95% Con~ (-, -) (-, -)
7 cox Hazard Rat~ <NA> <NA> 2.51
8 cox P-value <NA> <NA> 0.089
9 cox 95% CI of ~ <NA> <NA> (0.87,~
# ... with 2 more variables: ARM C <chr>,
# ARM D <chr>
=========================================================================
Create survival plot
=========================================================================
Create data frame with zero values for each visit
Create visit template
ARM AVISIT AVISITN cured
1 ARM A Week 16 16 FALSE
2 ARM A Week 12 12 FALSE
3 ARM A Week 4 4 FALSE
4 ARM A Week 6 6 FALSE
5 ARM A Week 2 2 FALSE
6 ARM A Week 8 8 FALSE
7 ARM A Week 0 0 FALSE
8 ARM B Week 16 16 FALSE
9 ARM B Week 12 12 FALSE
10 ARM B Week 4 4 FALSE
11 ARM B Week 6 6 FALSE
12 ARM B Week 2 2 FALSE
13 ARM B Week 8 8 FALSE
14 ARM B Week 0 0 FALSE
15 ARM C Week 16 16 FALSE
16 ARM C Week 12 12 FALSE
17 ARM C Week 4 4 FALSE
18 ARM C Week 6 6 FALSE
19 ARM C Week 2 2 FALSE
20 ARM C Week 8 8 FALSE
21 ARM C Week 0 0 FALSE
22 ARM D Week 16 16 FALSE
23 ARM D Week 12 12 FALSE
24 ARM D Week 4 4 FALSE
25 ARM D Week 6 6 FALSE
26 ARM D Week 2 2 FALSE
27 ARM D Week 8 8 FALSE
28 ARM D Week 0 0 FALSE
Calculate cummulative sum and percent
select: dropped 7 variables (USUBJID, SEX, AGEGR1, AGE, TRTA, <U+0085>)
group_by: 3 grouping variables (ARM, AVISIT, AVISITN)
summarize: now 29 rows and 4 columns, 2 group variables remaining (ARM, AVISIT)
group_by: one grouping variable (ARM)
mutate (grouped): changed 4 values (14%) of 'AVISIT' (0 new NA)
new variable 'csumc' (integer) with 13 unique values and 0% NA
distinct (grouped): removed one row (3%), 28 rows remaining
mutate (grouped): new variable 'pct' (double) with 16 unique values and 0% NA
# A tibble: 28 x 6
# Groups: ARM [4]
ARM AVISIT AVISITN sumc csumc pct
<chr> <chr> <dbl> <int> <int> <dbl>
1 ARM A Day 1 B~ 0 0 0 0
2 ARM A Week 2 2 0 0 0
3 ARM A Week 4 4 1 1 0.0278
4 ARM A Week 6 6 3 4 0.111
5 ARM A Week 8 8 1 5 0.139
6 ARM A Week 12 12 0 5 0.139
7 ARM A Week 16 16 0 5 0.139
8 ARM B Day 1 B~ 0 0 0 0
9 ARM B Week 2 2 1 1 0.0263
10 ARM B Week 4 4 4 5 0.132
# ... with 18 more rows
Generate plot
=========================================================================
Create and print report
=========================================================================
Create Report
Write out the report
# A report specification: 2 pages
- file_path: 'output/example5.rtf'
- output_type: RTF
- units: inches
- orientation: landscape
- margins: top 1 bottom 1 left 1 right 1
- line size/count: 9/40
- page_header: left=Sponsor: Client right=Study: ABC/BBC
- footnote 1: 'Program: Surv_Table.R'
- footnote 2: '* Success: PSGA <= 1: PSGA > 1'
- footnote 3: '** Based on R survival package survfit() function'
- footnote 4: '*** Based on proportional hazards model with treatment indicator variables as explanatory variables'
- footnote 5: 'Note: The end-point is cure of the disease (PSGA <= 1).'
- footnote 6: ' The probability of remaining diseased (PSGA > 1) defines the survival function'
- footnote 7: 'Note: A subject who is not cured by the end of 12 weeks or is lost to follow provides a censored observation for the analysis.'
- footnote 8: '"-" = Not Applicable'
- page_footer: left=Date Produced: 21Nov21 15:30 center= right=Page [pg] of [tpg]
- content:
# A table specification:
- data: tibble 'count_block' 2 rows 6 cols
- show_cols: all
- use_attributes: all
- width: 9
- title 1: 'Table 5.0'
- title 2: 'Analysis of Time to Initial PSGA Success* in Weeks'
- title 3: 'Safety Population'
- define: block visible='FALSE'
- define: label '' width=4.25
- define: ARM A
- define: ARM B
- define: ARM C
- define: ARM D
# A table specification:
- data: tibble 'stat_block' 9 rows 7 cols
- show_cols: all
- use_attributes: all
- width: 9
- headerless: TRUE
- stub: block label1 label2 width=4.25 align='left'
- define: block dedupe='TRUE'
- define: label1
- define: label2
- define: ARM A
- define: ARM B
- define: ARM C
- define: ARM D
# A plot specification:
- data: 28 rows, 7 cols
- layers: 2
- height: 3.5
- width: 9
- title 1: 'Figure 5.0'
- title 2: 'Kaplan-Meier Plot for Time to Initial PSGA Success (PSGA <= 1)'
- title 3: 'Safety Population'
=========================================================================
Clean Up
=========================================================================
=========================================================================
Log End Time: 2021-11-21 15:30:39
Log Elapsed Time: 0 00:00:02
=========================================================================